America’s Seed Fund powered by NSF awards $200 million annually to startups and small businesses, transforming scientific discovery into products and services with commercial and societal impact.
America’s Seed Fund is congressionally mandated through the Small Business Innovation Research (SBIR) program. The NSF is an independent federal agency with a budget of about $8.1 billion that supports fundamental research and education across all fields of science and engineering.
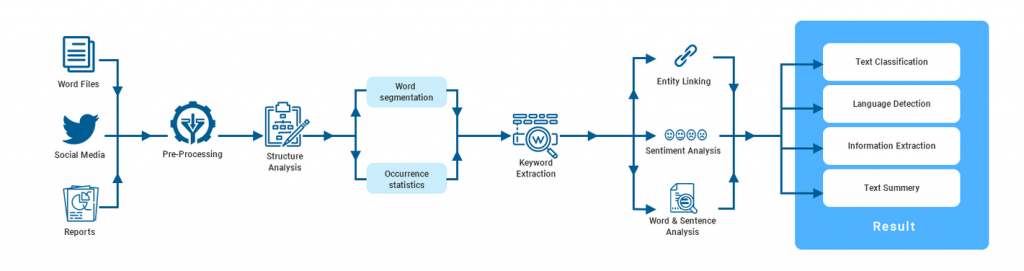
WISRAN uses Natural Language, Artificial Intelligence and Machine Learning to reveal the structure and meaning of text. You can extract information about people, places, and events, and better understand sentiment and customer conversations. Natural Language enables you to analyze text and also integrate it with your document storage on Google Cloud Storage.
Services
Insights robot
The powerful pre-trained robot help you understand content including sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis.
Domain specific insights
The service trains your own domain specific models to classify, extract, and detect sentiment with minimum effort using machine learning and Natural Language expertise.
Benefits
Insights from customers
Provides entity analysis to find and label fields within a document — including emails, chat, and social media — and then sentiment analysis to understand customer opinions to find actionable product and UX insights.
Extract key document entities that matter
Provides custom entity extraction to identify domain-specific entities within documents — many of which don’t appear in standard language models — without having to spend time or money on manual analysis.
Multimedia and multilingual support
Combines Natural Language with Speech-to-Text to extract insights from audio conversations. Uses it with optical character recognition (OCR) to understand scanned documents. Extract entities and understand sentiments in multiple languages.
Receipts and invoice understanding
Provides entity extraction that can identify common entries in receipts and invoices — dates, phone numbers, companies, prices, and so on — to help you understand the relationships between a request and proof of payment. It even validates addresses with Google Maps.
Features
Syntax analysis
Extract tokens and sentences, identify parts of speech, and create dependency parse trees for each sentence.
Entity analysis
Identify entities within documents — including receipts, invoices, and contracts — and label them by types such as date, person, contact information, organization, location, events, products, and media.
Custom entity extraction
Identify entities within documents and label them based on your own domain-specific keywords or phrases.
Sentiment analysis
Understand the overall opinion, feeling, or attitude sentiment expressed in a block of text.
Custom content classification
In addition to 700+ predefined categories, create labels to customize models for unique use cases, using your own training data.